
A Novel Method for Validating Addresses Using String Distance Metrics

DOI:
https://doi.org/10.54060/jmce.v3i2.36Keywords:
Address Validation, Address Matching, Natural Language Processing, GeocodingAbstract
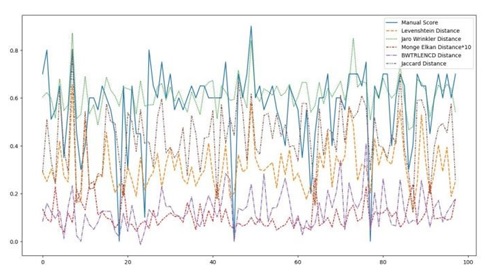
Address validation is vital since it confirms the quality and geographical precision of addresses used by organizations that rely on location-dependent and delivery-based services. Suppose addresses need to be thoroughly checked in advance. In that case, there may be difficulties with them, such as missing components or geographical defi-ciencies, which may lead to severe problems with logistics. When doing address valida-tion, discovering missing or incorrect address components is a beneficial aspect in mini-mizing the likelihood of service problems while saving time and money for organiza-tions. When it comes to addressing validation, using statistical metrics like correlation coefficients and measures of central tendency has been discovered to have a significant amount of untapped potential. In order to obtain a normalized score that is based on statistical similarities, the approach that is suggested in this study makes use of a mix-ture of several string-matching metrics. This score may then be used to exclude authen-ticated addresses based on the needed minimum level of similarity, which can be calcu-lated. Experiments have been carried out on a healthcare dataset taken from the actual world to show the efficacy of the suggested method in terms of accuracy and precision.
Downloads
References
S. Coetzee and A. K. Cooper, “Value of addresses to the economy, society and governance-A South African perspective,” in Proceedings of the 45th Annual Conference of the Urban and Regional Information Systems Association (URISA), Washington, DC, USA, 2007, pp. 20–23.
“Geocoding API overview,” Google for Developers. [Online]. Available: https://developers.google.com/maps/documentation/geocoding/overview. [Accessed: 09- May 2023).
Y. Guermazi, S. Sellami, and O. Boucelma, “A RoBERTa based approach for address validation,” in New Trends in Database and Information Systems, Cham: Springer International Publishing, 2022, pp. 157–166..
P. Christen and D. Belacic. “Automated probabilistic address standardisation and verification”. In: Australasian Data Mining Conference (AusDM’05), pages 53–67, Sydney, 2005.
M. Wang, V. Haberland, A. Yeo, A. Martin, J. Howroyd, and J. M. Bishop. “A probabilistic address parser using conditional random fields and stochastic regular grammar”. In: 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), pp. 225–232, 2016.
H. Zhang, F. Ren, H. Li, R. Yang, S. Zhang, and Q. Du. “Recognition method of new address elements in chinese address matching based on deep learning”. In: ISPRS International Journal of Geo-Information, vol. 9, no. 12, p. 745, 2020.
P. William Cohen and S. Ravikumar, “A comparison of string metrics for matching names and records,” KDD Workshop on Data Cleaning and Object Consolidation, vol. 3, pp. 73–78, 2003.
A. Rasool, A. Tiwari, G. Singla, and N. Khare, “String Matching Methodologies: A Comparative Analysis. ”,” International Journal of Computer Science and Information Technologies, vol. 3, no. 2, pp. 3394–3397, 2012.
S. Zhang, Y. Hu and G. Bian, "Research on string similarity algorithm based on Levenshtein Distance". In: 2017 IEEE 2nd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, pp. 2247-2251, 2017.
Y. Wang, J. Qin, and W. Wang, “Efficient approximate entity matching using Jaro-Winkler distance,” in Lecture Notes in Computer Science, Cham: Springer International Publishing, 2017, pp. 231–239.
J. Wang, G. Li and J. Fe, "Fast-join: An efficient method for fuzzy token matching based string similarity join". In: 2011 IEEE 27th International Conference on Data Engineering, Hannover, Germany, pp. 458-469, 2011.
S. Jimenez, C. Becerra, A. Gelbukh, and F. Gonzalez, “Generalized Mongue-Elkan Method for Approximate Text String Comparison”,” in Computational Linguistics and Intelligent Text Processing, vol. 5449, A. Gelbukh, Ed. Berlin, Heidelberg: Springer, 2009..
G. Manzini, “The Burrows-Wheeler Transform: Theory and Practice”,” in Mathematical Foundations of Computer Science. MFCS, vol. 1672, M. Kutyłowski, L. Pacholski, and T. Wierzbicki, Eds. Berlin, Heidelberg: Springer, 1999.
I. Allen, R. D. De Veaux, and R. N. S. Fienberg, Eds., STS) includes advanced textbooks from 3rd- to 4th-year undergraduate levels to 1st- to 2nd-year graduate levels. Exercise sets should be included. The series editors are currently Genevera. George Casella. (accessed May 2023).
Pradhan Mantri Jan Arogya Yojana (PM-JAY)- Locations and Addresses of Empanelled Hospitals. Available online: https://hospitals.pmjay.gov.in/mapsPlotting.htm (accessed May 2023
Downloads
Published
How to Cite
CITATION COUNT
Issue
Section
License
Copyright (c) 2023 Dr. H. P. Ghongade, Dr. A. A. Bhadre

This work is licensed under a Creative Commons Attribution 4.0 International License.












